
The EightThirtyTwo ISA – Part 17 – 2020-02-16
I was looking today at ways of improving the throughput of the EightThirtyTwo CPU. The design as it stands is very simple, and didn’t make any attempt to perform result forwarding or instruction fusing. These are both strategies for improving the performance of certain constructs, and I wasn’t sure which of these two techniques I should use.
In brief, without either mechanism implemented, when the CPU encounters code such as:
li 0
mr r0
it has to wait until the first instruction has finished writing to the tmp register before moving its new contents into the pipeline, and only then finally writing it to r0.
The two options I planned to explore were:
- Result Forwarding: when the immediate value leaves the ALU (where immediate values are built, six bits at a time), the CPU detects that the next instruction wants to use that value, and it’s routed to one of the ALU inputs, replacing a value that would normally be read from the register file. Thus the CPU no longer has to wait for the new value to complete its round trip back into the register file.
- Instruction Fusing: the CPU detects that the two instructions above could be fused into a single instruction, which will write both to the tmp register and to r0 at the same time. To avoid the complexity of doing a second fetch, the second instruction could just become a no-op – wasting just one cycle, rather than the several previously lost to the round-trip through the register file.
In preparation for testing these I took a closer look at a GTKWave trace of the CPU in action:
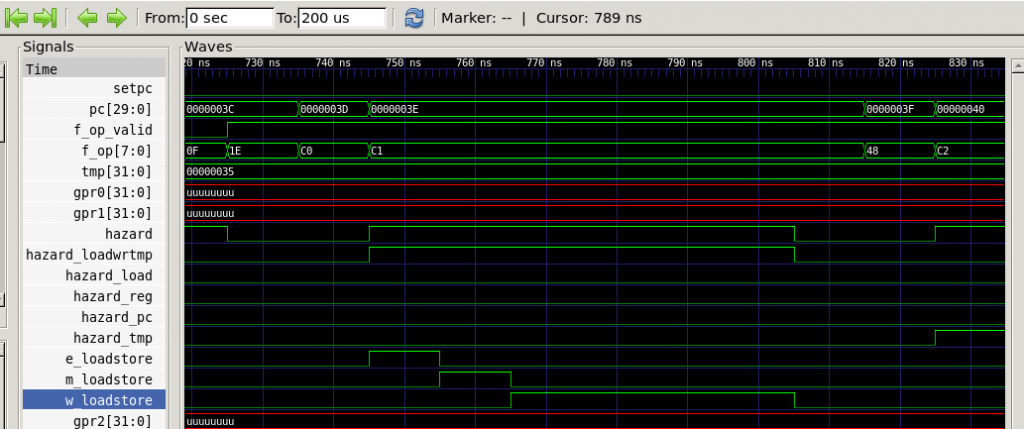
Hmmm, something’s not right here. I was expecting to see a pause after the c0 and c1 (load immediate) instructions, before the 48 (mr r0) instruction, but not one as long as that!
After a little thought I realised that the extended hazard that’s blocking the CPU at that point is due to the previous instruction, a “stdec r6” instruction that saves a return address on the stack. My hazard code was blocking anything that writes to tmp until after any loads had completed (which is necessary because loads also write to tmp, and the instructions must complete in the correct order) – but I wasn’t treating loads and stores separately in the hazard unit, so store operations were also blocking instructions that write to tmp. (The hazard I was expecting to address with Result Forwarding or Instruction Fusing is actually the next one, that begins at the right-hand edge of the trace!)
Having addressed this by separating loads and stores in the hazard logic, I then looked more closely at the speedup options.
Since logic footprint is still one of the driving goals of this project, I don’t want to implement anything too complicated, or anything that’s going to reduce the fmax significantly, since I want to be able to run the CPU on the same clock as a project’s SDRAM controller.
In order to cover the specific case I highlighted above, I decided to implement rudimentary result forwarding, covering just the q2 ALU output, feeding the d1 ALU input. The logic required to determine when it’s safe to do so is as simple as:
if interrupt='0' and thread.d_ex_op(e32_exb_q2totmp)='1' andthread.f_alu_reg1(e32_regb_tmp)='1' thenalu_forward_q2tod1<='1';end if
(I’m disallowing the results forwarding while an interrupt is pending because the interrupt could well break the pair of the instructions we’re accommodating with the forwarding.)
While there are many other cases we could address, we would then have to compare register numbers, and forward into the ALU’s d2 input. I want to avoid doing that if I can because the d2 input is already multiplexed between vanilla and inverted versions of the source data, allowing the same adder to be used for addition, subtraction and comparison – so adding another level of multiplexing is going to negatively impact fmax.
Even so, with the limited forwarding supported by the code above, we avoid a hazard for any pairing of either li, mt or exg, with any of mr, exg, add, xor, ldidx and stmpdec. Here’s a trace of the same piece of code with these changes made:
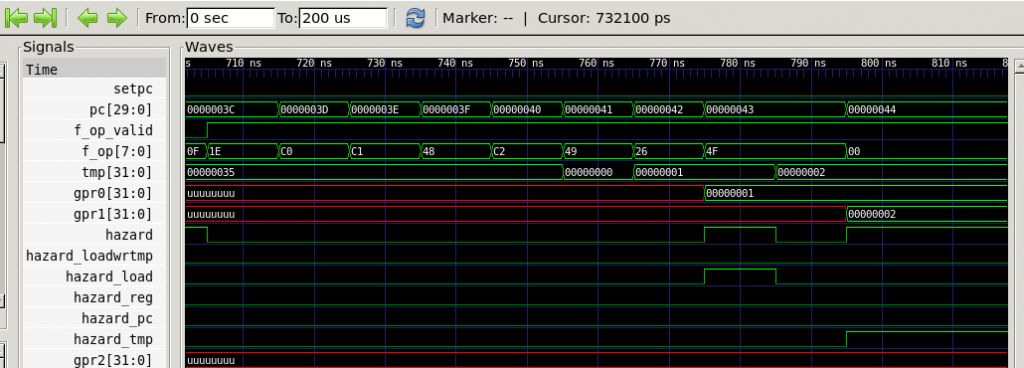
…and the now customary Dhrystone score!
User time: 831
Microseconds for one run through Dhrystone: 33
Dhrystones per Second: 30084
VAX MIPS rating * 1000 = 17117
(I must confess that I’m cheating very slightly here – the CPU doesn’t *quite* meet timing at 133MHz any more – with a negative slack of 0.101ns. I will do my best to fix that.)